

A data scientist in Computer Science
Hung Ngo is currently a lecturer of School of Management, Technological University Dublin (TUDublin, Ireland). His research interests are Knowledge Management, Data Mining, Data Analytics, and Natural Language Processing. He has involved many research topics, including machine translation, building ontology, text mining, linked data and internet of things.
He receives his PhD degree in Computer Science at University College Dublin (UCD, Ireland). He received the Msc and Bsc in Computer Science at University of Science, Vietnam National University - HoChiMinh City.
He has spent a short research stay belong to the research exchange program at the University of Vienna, Austria. Co-operations have been established to carry out the EVBCorpus project and EVBAlign project with Prof. Dinh Dien and Prof. Werner Winiwarter.
He got an internship programm in INSIGHT Center, Galway, Ireland in 2014. He has worked on the GraphOfThings project which is the knowledge graph of connected things. GraphOfThings is creating meaningful links among millions of physical and virtual things to create a dynamic knowledge graph that plays the role as insight for a real-time search engine for events happening around us. This project won the 2nd Award at Semantic Web Challenge 2014 at ISWC, Trentino, Italia.
He also got an internship in National Institute of Informatics, Japan supervised by Prof. Nigel Collier. Researches were involved in the BioCaster project and building geographical ontology. Integrating geo-ontology into the Global Health Monitor system, building the webpage for publishing project result;
Research Fields
Knowledge Management
- Ontology Engineering
- Knowledge Graph
- Linked Data
Natural Language Processing
- Named Entity Recognition
- Text Classification
- Bilingual Corpora
- Knowledge Graph
- Text Generation
- Machine Translation
Data Mining
- Classification
- Prediction
- Association
- Clustering
.
Agriculture Sector
- Agriculture Ontology
- Farming Data Analytics
Bioinformatic Sector
- Bio-Ontology
- Medical Named Entity Recognition
- Global Disease Monitoring
IoT Sector
- Linked Data
- Semantic Sensor Network
- Social Sensor Network
Brief Introduction

PhD researcher
Working at CONSUS Lab
Jan. 2018 ~ Current

TA/Demonstrator
Working at CS School
Jan. 2018 ~ Current

Internship
Worked at IoT-LMS lab
Jun. 2014 ~ Dec. 2014

Internship
Worked at CSLEARN lab
June. 2011 ~ July. 2011

Internship
Worked at Nigel Collier lab
Oct. 2006 ~ Mar. 2007

Lecturer
IT Lecturer at UIT-VNUHCM
Jun. 2006 ~ Present

Lecturer
IT Lecturer at CITD-VNUHCM
Oct. 2002 ~ Jun. 2006
Resume
19 Working Years
Education
Jan 2018 ~ Present
Ph.D. in Computer Science
University College Dublin, IrelandSchool: Computer Science
Dissertation: Ontology-based Knowledge Map Model for Knowledge Handling
Sep 2004 ~ December 2008
Master in Computer Science
VNUHCM-University of ScienceFaculty: Information Technology
Thesis: Automatic Searching English–Vietnamese Documents From The Internet
Sep 1998 ~ Sep 2002
Bachelor in Computer Science
VNUHCM-University of ScienceFaculty: Information Technology
Thesis: Word Alignment in English-Vietnamese Bilingual Text
Experience
Jan 2018 - Current
PhD Researcher
University College Dublin (Ireland)Jun 2014 - Dec 2014
Internship
INSIGHT Center, NUIG (Ireland)Oct 2006 - Mar 2007
Internship
National Institute of Informatics (Japan)Oct 2006 - Mar 2007
Internship
National Institute of Informatics (Japan)Jun 2006 - Current
IT Lecturer
VNUHCM-University of Information TechnologyOct 2002 - Jun 2006
IT Lecturer
VNUHCM-Center of Information Technology DevelopmentPersonal Skills
Negotiation
Presentation
Collaboration
Adaptability
Professional Skills
Research
Python
C/C++/C#
Java
NLTK, Sci-kitlearn
Tensorflow/Keras
Honors and Awards
SFI Scholarship for PhD (2018-2021)
2nd Award of the Semantic Web Challenge (2014)
Research Internship (2014)
ASEA-UNINET scholarship (2011)
NII International Internship (2006)
University College Dublin (UCD)
Dublin, Ireland
13th International Semantic Web Conference
Trentino, Italia
INSIGHT Center, NUIG
Galway, Ireland
Short research stay at the Research Group Data Analytics and Computing
University of Vienna, Austria
National Institute of Informatics
Tokyo, Japan
Industrial Units
-
FI Technology (Jan. 2017 - Dec. 2027)
- NLP/AI Expert
- Building WorldBiz, which is a news express application based on NLP techniques and existing news resources to deliver oriental news to specific users.
-
Robot3T Group (Feb. 2012 – Dec. 2013)
- Project Leader
- Building software to control industrial robots and automatic machines, such as book auto-scanner machines. These applications and machines are sold to industrial partners.
-
C&D Semiconductor (Jun. 2007 – Jun. 2009)
- Project Leader
- Building software to control wafer sorters, microscope loaders, bright light, and linear track machines in the semiconductor industry. The software and machines are widely sold out and used in industrial FAB in the US and over the world.
Teaching
19 Working Years
Teaching Modules
Jan 2018 ~ Present
Teaching Assistant / Demonstrator
University College Dublin, IrelandSchool of Computer Science
- Computer Programming I
- Python Programming
- Data and Database Forensics
- OSINT - Collection & Analysis
- Data Mining
- Cloud Computing
Jun 2006 ~ Jan 2018
IT Lecture
VNUHCM-University of Information TechnologyFaculty of Computer Science
- C/C++ Programming
- Data Structure and Algorithm
- Object-Oriented Programming
- Natural Language Processing
- Machine Translation
- Corpus Linguistics
- Semantic Web
Oct 2002 ~ Jun 2006
IT Lecture
VNUHCM-Center of Information Technology DevelopmentDepartment of Computer Science
- C/C++ Programming
- Data Structure and Algorithm
- Object-Oriented Programming
Bachelor Thesis Advisor
-
Quoc Thai Nguyen, Thoai Linh Nguyen (2020)
- Thesis title: Sentiment Analysis of Vietnamese Reviews.
- Faculty of Computer Science, University of Information Technology, VNUHCM, Vietnam
- 01 paper published in the IEEE NAFOSTED conference
-
Vu C.D. Hoang, Nguyen L. Nguyen (2006)
- Thesis title: Vietnamese Text Classification
- Faculty of Information Technology, University of Science, VNUHCM, Vietnam
- 01 paper published in the IEEE RIVF conference
-
Quoc Tri Tran, Xuan Thao Pham (2006)
- Thesis title: Named entity recognition in Vietnamese documents.
- Faculty of Information Technology, University of Science, VNUHCM, Vietnam
- 01 paper published in the Progress in Informatics journal
Research
Project Illustration
CONSUS - (2018-present)
CONSUS is a collaborative research partnership between University College Dublin (UCD) and Origin Enterprises PLC that has been supported through the Science Foundation Ireland (SFI) Strategic Partnership Programme. The €17.6 million five-year project will investigate digital, precision agriculture and crop science through a strong multi and inter-disciplinary approach that combines the leading expertise of UCD in data science and agricultural science with Origin’s integrated crop management research, systems, capabilities and extensive on-farm knowledge exchange networks.Tasks: Developing Ontology-based Knowledge Map model to handle Mining Knowledge for Digital Agriculture. This task requires several sub-tasks, such as building ontology, named entity recognition, entity linking, building RDF storage based on linked data techniques, and building knowledge browser.
GraphOfThings - (2014-2016)
 GraphOfThings is the knowledge graph of connected things. GraphOfThings (GoT) is creating meaningful links among millions of physical and virtual things to create a dynamic knowledge graph that plays the role as insight for a real-time search engine for events happening around us.
GraphOfThings is the knowledge graph of connected things. GraphOfThings (GoT) is creating meaningful links among millions of physical and virtual things to create a dynamic knowledge graph that plays the role as insight for a real-time search engine for events happening around us.Tasks: Integrating social media channel networks as virtual things into IoT streaming sources to create knowledge graph, GoT; and implementing visualization for GoT system as a Live Knowledge Graph;
Website is available at http://graphofthings.org/.
EVBCorpus - (2011-2013)
EVBCorpus - A Multi-Layer English-Vietnamese Bilingual Corpus for Studying Tasks in Comparative Linguistics and Machine Translation. The EVBCopus contains over 20,000,000 words (20 million) from 15 bilingual books, 100 parallel English-Vietnamese / Vietnamese-English texts, 250 parallel law and ordinance texts, 5,000 news articles, and 2,000 film subtitles. The composition, annotation, encoding and availability of the corpus are meant to facilitate developments of language technology and studies in bilingual terminology extraction, primarily for the English-Vietnamese-English language pair.The building EVBCorpus process includes four main steps: (1) collect data and align bitext at the paragraph level; (2) align bitext at the sentence level, (3) linguistic analysis and tagging; (4) annotate and correct corpus with toolkits. As result, the EVBCopus was aligned at the sentence level; and a part of this corpus containing 1,000 news articles was aligned semi-automatically at the word level.
For more information, please look at here.
BioCaster - (2006-2008)
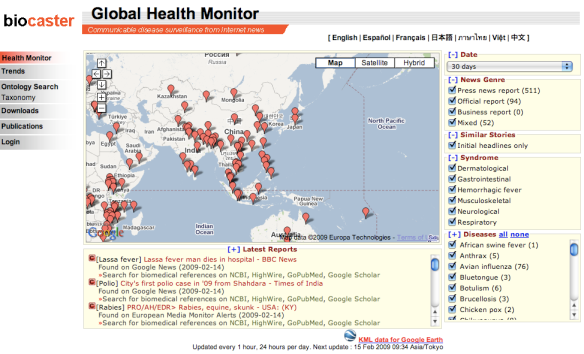 BioCaster is an ontology-based text mining system for detecting and tracking the distribution of infectious disease outbreaks from linguistic signals on the Web. The system continuously analyzes documents reported from over 1700 RSS feeds, classifies them for topical relevance and plots them onto a Google map using geocoded information. The system consists of four main stages: topic classification, named entity recognition (NER), disease/location detection and event recognition.
BioCaster is an ontology-based text mining system for detecting and tracking the distribution of infectious disease outbreaks from linguistic signals on the Web. The system continuously analyzes documents reported from over 1700 RSS feeds, classifies them for topical relevance and plots them onto a Google map using geocoded information. The system consists of four main stages: topic classification, named entity recognition (NER), disease/location detection and event recognition.Main tasks: Building geographical ontology, integrating geo-ontology into the Global Health Monitor system, and building the webpage for publishing research result.
The BioCaster map and ontology are freely available via a web portal at http://www.biocaster.org (live update until 2012).
Publications
Progestious papers
- Quoc Hung Ngo, Tahar Kechadi, and Nhien-An Le-Khac, (2022). Knowledge representation in digital agriculture: A step towards standardised model. Computers and Electronics in Agriculture, vol. 199, August 2022, 107127, 2022, Elsevier. DOI: https://doi.org/10.1016/j.compag.2022.107127.
- Quoc Hung Ngo, Tahar Kechadi, and Nhien-An Le-Khac, (2021). Domain Specific Entity Recognition with Semantic-based Deep Learning Approach. IEEE Access, vol. 9, pp. 152892-152902, 2021. DOI: 10.1109/ACCESS.2021.3128178.
- Quoc Hung Ngo, Tahar Kechadi, and Nhien-An Le-Khac (2020). OAK: Ontology-based Knowledge Map Model for Digital Agriculture. In: Dang T.K., Küng J., Takizawa M., Chung T.M. (eds) Future Data and Security Engineering. FDSE 2020. Lecture Notes in Computer Science, vol 12466. Springer, Cham. pp. 245-259. DOI: 10.1007/978-3-030-63924-2_14.
- Quoc Thai Nguyen, Thoai Linh Nguyen, Ngoc Hoang Luong, and Quoc Hung Ngo, (2020). Fine-Tuning BERT for Sentiment Analysis of Vietnamese Reviews. 2020 7th NAFOSTED Conference on Information and Computer Science (NICS 2020), IEEE, pp.302-307, DOI:10.1109/NICS51282.2020.9335899.
- Quoc Hung Ngo, Nhien-An Le-Khac, and Tahar Kechadi (2019). Predicting Soil pH by Using Nearest Fields. In AI-2019 Thirty-ninth SGAI International Conference on Artificial Intelligence, Springer, LNAI 11927, pp. 480-486. DOI: 10.1007/978-3-030-34885-4_40.
- Quoc Hung Ngo, Nhien-An Le-Khac, and Tahar Kechadi, (2018). Ontology Based Approach for Precision Agriculture. In International Conference on Multi-disciplinary Trends in Artificial Intelligence, pp. 175-186. Springer, LNCS, volume 11248, 2018. DOI: 10.1007/978-3-030-03014-8_15.
- Song Nguyen Duc Cong, Quoc Hung Ngo, Rachsuda Jiamthapthaksin, (2016). State-of-the-Art Vietnamese Word Segmentation, In Proceedings of the 2017 International Conference on Science in Information Technology (ICSITech), pp. 119-124, IEEE Computer Society, 2016.
- Danh Le-Phuoc, Hoan Nguyen Mau Quoc, Quoc Hung Ngo, Tuan Tran Nhat, Manfred Hauswirth, (2016). The Graph of Things: A step towards the Live Knowledge Graph of connected things, Web Semantics: Science, Services and Agents on the World Wide Web 37, Volumes 37–38, March 2016, pp. 25–35.
- Thuy Ngan Nguyen Luu, Quoc Hung Ngo, Quoc Minh Nghiem, (2016). Machine Translation, VNU-HCM Publishing House, 2016 (Vietnamese).
- Danh Le Phuoc, Hoan Nguyen Mau Quoc, Quoc Hung Ngo, Tuan Tran Nhat, Manfred Hauswirth, (2014). Enabling Live Exploration on The Graph of Things, Semantic Web Challenge 2014, Trento, Italia, 19-23 October 2014.
- Quoc Hung Ngo, Dinh Dien, Werner Winiwarter, (2014). Building English-Vietnamese Named Entity Corpus with Aligned Bilingual News Articles, In Proceedings of the 5th Workshop on South and Southeast Asian Natural Languages Processing (5th WSSANLP within the COLING2014). Association for Computational Linguistics, pp. 85-93, 2014.
- Quoc Hung Ngo, Dinh Dien, Werner Winiwarter, (2013). A Hybrid Method for Word Segmentation with English-Vietnamese Bilingual Text, In Proceedings of the 2013 International Conference on Control, Automation and Information Sciences (ICCAIS2013), pp. 48-52, IEEE Computer Society, 2013.
- Quoc Hung Ngo, Werner Winiwarter, Bartholomaus Wloka, (2013). EVBCorpus - A Multi-Layer English-Vietnamese Bilingual Corpus for Studying Tasks in Comparative Linguistics, In Proceedings of the 11th Workshop on Asian Language Resources (ALR11), IJCNLP2013 Workshop, pp. 1-9. AFNLP, 2013.
- Quoc Hung Ngo, Dinh Dien, Werner Winiwarter, (2012). Automatic Searching for English-Vietnamese Documents on the Internet, In Proceedings of the 3rd Workshop on South and Southeast Asian Natural Languages Processing (3rd WSSANLP within the COLING2012), pp. 211-220. Association for Computational Linguistics, 2012.
- Quoc Hung Ngo, Werner Winiwarter, (2012). Building an English-Vietnamese Bilingual Corpus for Machine Translation, In Proceedings of the International Conference on Asian Language Processing 2012 (IALP 2012), IEEE Computer Society, pp. 157-160.
- Quoc Hung Ngo, Son Doan, and Werner Winiwarter (2012). Using Wikipedia for Extracting Hierarchy and Building Geo-Ontology, In the International Journal of Web Information Systems, Vol. 8, Issue 4, pp. 401-412.
- Quoc Hung Ngo, Werner Winiwarter (2012). A Visualizing Annotation Tool for Semi-Automatically Building a Bilingual Corpus, In Proceedings of the 5th Workshop on Building and Using Comparable Corpora, LREC2012 Workshop, pages 67-74. Association for Computational Linguistics, 2012.
- Quoc Hung Ngo, Son Doan, and Werner Winiwarter (2011). Building a Geographical Ontology by Using Wikipedia. In Proceedings of the 13th International Conference on Information Integration and Web-based Applications & Services, pages 345-348. ACM, 2011.
- Nigel Collier, Son Doan, Ai Kawazeo, Reiko Matsuda Goodwin, Mike Conway, Yoshio Tateno, Quoc Hung Ngo, Dinh Dien, Asanee Kawtrakul, Koichi Takeuchi, Mika Shigematsu, Kiyosu Taniguchi (2008), BioCaster: detecting public health rumors with a Web-based text mining system, Bioinformatics, Oxford University Press, DOI: 10.1093/bioinformatics/btn534.
- Son Doan, Quoc Hung Ngo, Ai Kawazoe and Nigel Collier (2008), The Use of the BioCaster Ontology for Mapping Infectious Diseases and Locations in the BioCaster Surveillance System, BioLINK 2008, Toronto, Canada, July 2008.
- Son Doan, Quoc Hung Ngo, Nigel Collier (2008), Building and Using Geographical Ontology in the BioCaster Biosurveillance System, Workshop on Bio-Ontologies 2008: Knowledge in Biology, July 2008.
- Son Doan, Quoc Hung Ngo, Ai Kawazoe and Nigel Collier (2008), Global Health Monitor - A Web-based System for Detecting and Mapping Infectious Diseases, In Proceedings of the International Joint Conference on Natural Language Processing (IJCNLP), Companion Volume, pp. 951-956.
- Nigel Collier, Ai Kawazoe, Son Doan, Mika Shigematsu, Kiyosu Taniguchi, Lihua Jin, John McCrae, Hutchatai Chanlekha, Dinh Dien, Quoc Hung, Van Chi Nam, Koichi Takeuchi, DEng, Asanee Kawtrakul (2007), Detecting Web Rumours with a Multilingual Ontology-Supported Text Classification System, In Proceedings of the 2007 International Society for Disease, Indianapolis, Indiana, United States, October 11th-12th.
- Nigel Collier, Ai Kawazoe, Mika Shigematsu, Kiyosu Taniguchi, Lihua Jin, John McCrae, Dinh Dien, Quoc Hung, Koichi Takeuchi, Asanee Kawtrakul (2007), Ontology-driven influenza surveillance from Web rumours, In Proceedings of the 2007 Options for the Control of Influenza VI (Options), pp. 225-226, Toronto, Ontario, Canada, June 17th-23rd.
- C.D. Vu Hoang, L. Nguyen Nguyen, Q. Hung Ngo, 2007, A Comparative Study on Vietnamese Text Classification Methods. In Proceedings of the 5th International Conference on Research, Innovation& Vision for the Future, March 2007, Hanoi, Vietnam.
- Q. Tri Tran, T. X. Thao Pham, Q. Hung Ngo, Dien Dinh and Nigel Collier (2007), Named entity recognition in Vietnamese documents, Progress in Informatics, No.4, March 2007, pp. 5-13.
- Dinh Dien, Pham Phu Hoi, Ngo Quoc Hung. 2003. Some Lexical Issues in Building Electronic Vietnamese Dictionary, PAPILLON-2003 Workshop on Multilingual Lexical Databases, Hokkaido University, Japan.
- D. Dien, H. Kiem, T. Ngan, X. Quang, Q. Hung, P. Hoi, V. Toan. 2002. Word alignment in English - Vietnamese bilingual corpus, In Proceedings of EALPIIT'02 (the 2nd East-Asian Language Processing and Internet Information Technology), Hanoi, Vietnam, Jan 2002, pp. 3-11
EVBCorpus
English-Vietnamese Bilingual Corpus
EVBCorpus - A Multi-Layer English-Vietnamese Bilingual Corpus for Studying Tasks in Comparative Linguistics and Machine Translation. The EVBCopus contains over 20,000,000 words (20 million) from 15 bilingual books, 100 parallel English-Vietnamese / Vietnamese-English texts, 250 parallel law and ordinance texts, 5,000 news articles, and 2,000 film subtitles. The composition, annotation, encoding and availability of the corpus are meant to facilitate developments of language technology and studies in bilingual terminology extraction, primarily for the English-Vietnamese-English language pair.
The building EVBCorpus process includes four main steps: (1) collect data and align bitext at the paragraph level; (2) align bitext at the sentence level, (3) linguistic analysis and tagging; (4) annotate and correct corpus with toolkits. As result, the EVBCopus was aligned at the sentence level; and a part of this corpus containing 1,000 news articles was aligned semi-automatically at the word level.
| Source | Document | Paragraph | Sentence | Word |
| ------------------------------------------------------------------------------------------ | ||||
| En-Vn Books | 15 | 14,195 | 61,167 | 1,335,180 |
| En-Vn Fictions | 100 | 192,898 | 489,787 | 6,129,161 |
| En-Vn Laws | 250 | 86,848 | 98,064 | 1,981,932 |
| En-Vn ETests | 500 | 20,288 | 21,575 | 411,093 |
| En-Vn News | 5,000 | 94,933 | 173,903 | 2,965,590 |
| En-Vn Subtitles | 2,000 | 1,302,839 | 1,447,581 | 8,150,080 |
| ------------------------------------------------------------------------------------------- | ||||
| Total | 7,865 | 1,712,001 | 2,292,077 | 20,973,036 |
| Source | Document | Paragraph | Sentence | Word |
| ----------------------------------------------------------------------------------------- | ||||
| En-Vn Books | 15 | 13,980 | 80,323 | 1,375,492 |
| En-Vn Fictions | 100 | 192,723 | 491,703 | 6,307,613 |
| En-Vn Laws | 250 | 86,803 | 98,102 | 1,912,055 |
| En-Vn News | 1,000 | 24,523 | 45,531 | 740,534 |
| ----------------------------------------------------------------------------------------- | ||||
| Total | 1,365 | 318,029 | 715,659 | 10,431,592 |
The EVWACorpus contains 1,000 news articles with 45,531 sentence pairs and 740,534 words which are aligned manually at the word level between English and Vietnamese sentence.
| English | Vietnamese | |
| ------------------------------------------------------------- | ||
| Files | 1,000 | 1,000 |
| Sentences | 45,531 | 45,531 |
| Words | 740,534 | 832,441 |
| Sure Alignments | 447,906 | 447,906 |
| Possible Alignments | 560,215 | 560,215 |
| Words in Alignments | 654,060 | 768,031 |
| ------------------------------------------------------------- | ||
The EVChkCorpus contains 1,000 news articles with 45,531 sentence pairs. It is tagged 5 raw chunker tags in both English and Vietnamese text. Details of the EVChkCorpus:
| # | English | Vietnamese | |
| ----------------------------------------------------------------------- | |||
| NP | Noun Phrase | 212,500 | 209,824 |
| VP | Verb Phrase | 90,784 | 123,600 |
| PP | Preposition Phrase | 79,853 | 70,457 |
| ADVP | Adjective Phrase | 18,318 | |
| ADJP | Adverb Phrase | 8,367 | 15,104 |
| ----------------------------------------------------------------------- | |||
The EVNECorpus contains 1,000 news articles with 45,531 sentence pairs. It is tagged named entities in both English and Vietnamese text. Details of the EVNECorpus:
| English | Vietnamese | ||
| ------------------------------------------------------------- | |||
| LOC | Location | 10,115 | 10,006 |
| PER | Person | 6,869 | 6,741 |
| ORG | Oganization | 7,837 | 7,549 |
| PCT | Percentage | 1,107 | 921 |
| MON | Money | 898 | 823 |
| TIM | Time | 4,244 | 4,100 |
| ------------------------------------------------------------- | |||
| Total | 35,879 | 34,732 | |
Quoc Hung Ngo, Werner Winiwarter, Bartholomaus Wloka, (2013). EVBCorpus - A Multi-Layer English-Vietnamese Bilingual Corpus for Studying Tasks in Comparative Linguistics, In Proceedings of the 11th Workshop on Asian Language Resources (ALR11), IJCNLP2013 Workshop, pp. 1-9. AFNLP, 2013.
Quoc Hung Ngo, Werner Winiwarter, (2012). Building an English-Vietnamese Bilingual Corpus for Machine Translation, In Proceedings of the International Conference on Asian Language Processing 2012 (IALP 2012), IEEE Computer Society, pp. 157-160.
Quoc Hung Ngo, Dinh Dien, Werner Winiwarter, (2014). Building English-Vietnamese Named Entity Corpus with Aligned Bilingual News Articles, In Proceedings of the 5th Workshop on South and Southeast Asian Natural Languages Processing (5th WSSANLP within the COLING2014). Association for Computational Linguistics, pp. 85-93, 2014.
Quoc Hung Ngo, Werner Winiwarter (2012). A Visualizing Annotation Tool for Semi-Automatically Building a Bilingual Corpus, In Proceedings of the 5th Workshop on Building and Using Comparable Corpora, LREC2012 Workshop, pages 67-74. Association for Computational Linguistics, 2012.
Quoc Hung Ngo, Dinh Dien, Werner Winiwarter, (2012). Automatic Searching for English-Vietnamese Documents on the Internet, In Proceedings of the 3rd Workshop on South and Southeast Asian Natural Languages Processing (3rd WSSANLP within the COLING2012), pp. 211-220. Association for Computational Linguistics, 2012.
- Trieu, Hai Long, Vu Tran, and Nguyen Le Minh. "Investigating phrase-based and neural-based machine translation on low-resource settings." Proceedings of the 31st Pacific Asia Conference on Language, Information and Computation. 2017.
- Trieu, Long Hai. "A Study On Machine Translation For Low-Resource Languages". Thesis of Doctor of Philosophy, JAIST, 2017.
- Phuoc, Nguyen Quang, Yingxiu Quan, and Cheol-Young Ock. "Building a bidirectional English-Vietnamese statistical machine translation system by using MOSES." International Journal of Computer and Electrical Engineering 8.2 (2016): 161.
- Song Cong Nguyen Duc; Q.Hung Ngo; JIAMTHAPTHAKSIN, Rachsuda. State-of-the-art Vietnamese word segmentation. In: Science in Information Technology (ICSITech), 2016 2nd International Conference on. IEEE, 2016. p. 119-124.
- Nguyen, L. H., Dinh, D., & Tran, P. (2016). An Approach to Construct a Named Entity Annotated English-Vietnamese Bilingual Corpus. ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP), 16(2), 9.
- Dawborn, Timothy James. "DOCREP: Document Representation for Natural Language Processing." Thesis of Doctor of Philosophy, The University of Sydney, 2015.
- Lam, Khang Nhut. "Automatically creating multilingual lexical resources." Proceedings of the Nineteenth AAAI/SIGAI Doctoral Consortium. 2014.
- Huy, Dang Ngoc, and Pusadee Seresangtakul. "Vietnamese-Thai Lexicon for Machine Translation." The Tenth Symposium on Natural Language Processing (SNLP2013), Phuket, Thailand. 2013.
- GIANG, Lam Tung; HUNG, Vo Trung; PHAP, Huynh Cong. Experiments with query translation and re-ranking methods in Vietnamese-English bilingual information retrieval. In: Proceedings of the Fourth Symposium on Information and Communication Technology. ACM, 2013. p. 118-122.